| Follow @ProbabilityPuz |  |
Statistics: A good book to learn statistics
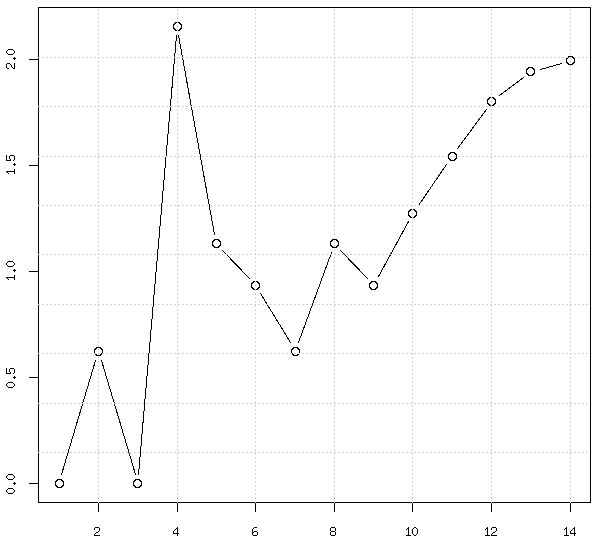
As an example data set consider some dummy data shown in the table/chart below. Notice, value 33 is an outlier. When charted. you can see there is some non-linearity in the data too, for higher values of \(x\)

$$
\hat{y} = \frac{y^{\lambda} - 1}{\lambda}
$$
The value of lambda needs to be chosen optimally that maximizes the log likelihood that would make the time series more like it came from a normal distribution. Most statistical tools out there do it for you. In R, the function "boxcox" in the package "MASS" does it for you. The following code snippet computes the optimal value of \(\lambda\) as -0.30303

Let's apply this transformation to the data and see how it looks on a chart.
$$
e = \sum_{i=1}^{N}\frac{(y_{actual} - \alpha_{0} - \alpha_{1}x)^2}{N}
$$
where \(N\) is the number of points. We can tweak the above equation to minimize as follows
$$
e = \sum_{i=1}^{N}\frac{(y_{actual} - \alpha_{0} - \alpha_{1}x)^2}{N} + \lambda(\alpha_{0}^2 + \alpha_{1}^2)
$$
The tweaked error equation forces towards choices of \(\alpha_{0}, \alpha_{1}\) where they cannot take larger values. The optimal value of \(\lambda\) needs to be ascertained by tuning. A formulaic solution does not exist, so we use another tool in R, the function "optim". This function lets you do basic optimization and minimizes any function you pass it, along with required parameters. It returns parameter values that minimize this function. The actual usage of this function isn't exactly intuitive. Most examples on the internet talk of minimizing a proper well formed function. Most real life applications involve minimizing functions having lots of parameters and additional data. The funct"optim" accepts the "..." argument which is a means to pass through arguments to the function you want to minimize. So here is how you would do it in R, all of it.

The above code walks through this example by calling optim. It finally outputs the fits in original domain using all three methods
- The grey line represents the fit if you simply used "lm"
- The red line represents the fit if you transformed the data and used "lm" in the transformed domain but without regularization. Note: you are clearly worse off.
- The blue dotted line shows the fit if you used transformation and regularization, clearly a much better fit

The function "optim" has lots of methods that it uses for finding the minimum value of the function. Typically, you may also want to poke around with the best value of \(\lambda\) in the minimization function to get better fits.
If you are looking to buy some books on time series analysis here is a good collection. Some good books to own for probability theory are referenced here
I think there's something wrong with the red fit (transformed response). Just did it myself and got y.hat = c(1.505845, 1.724990, 1.987590, 2.304775, 2.691234, 3.166601, 3.757496, 4.500575, 5.447183, 6.670643, 8.277932, 10.428961, 13.369481, 17.489335)
ReplyDeleteRight. Corrected. Thanks for pointing out.
DeleteGood! Just was surprised by how bad the fit was, it's not "clearly worse off" anymore :-)
DeleteThis example has no context so modelling decisions are being made in a vacuum. That never happens in real life.
ReplyDeleteTransforming your way around outliers (if that's what you have - only a context would shed light on this) is never a really good idea. Why not recognize hat you have an outlier and use a robust method. E.g.
dfr <- data.frame(x = x, y = y) ## put things together that belong together...
library(robustbase)
mrob <- lmrob(y ~ poly(x, 3), dfr)
summary(mrob) ## shows one outlier, as expected
plot(y ~ x, dfr, type = "b")
lines(predict(mrob, dfr) ~ x, dfr, col = "blue")
This model has 4 mean parameters + 1 variance, and so is comparable with yours which has 2 reg coeffs + 1 transform + 1 tuning constant + 1 variance.
I don't think either model would be much good for extrapolation, though.